5 to 18: Why Your Count Might Be Off by One
Quick question:
How many numbers are there from 5 to 18, including both ends?
Your first instinct might be to subtract:
18 - 5 = 13
Feels right.
But it’s wrong.
It’s a small thing, and kind of basic, but this mistake got me more times than I’d like to admit. Eventually I learned how to count ranges properly. :)
Basic counting
Let’s start with something simpler.
How many numbers are in this list?
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13
You’d probably say 13 without counting. And you’d be absolutely right.
That kind of range is easy. Our brain sees the pattern and knows what’s going on. We’ve been counting this way since we were little kids. But that instinct quietly fails in cases like 5 to 18.
So, how many numbers are there between 5 and 18 inclusive?
Let’s count manually
Here’s the full list from 5 to 18:
5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18
That’s 14 numbers, not 13. So what went wrong with our subtraction?
Try a quick trick
Let’s take the above list from 5 to 18 and turn it into a list that we know how to count by subtracting 4 from every number (I first saw this approach in David Patrick’s book Introduction to Counting & Probability. A great resource if you enjoy these kinds of problems.):
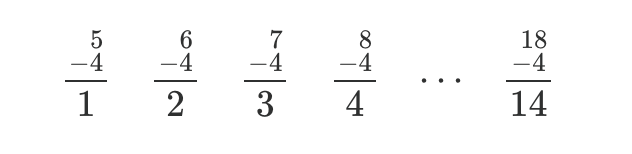
Much easier to count! It has 14 items. Since we only shifted the numbers to start at 1 (without changing the count), the original list has 14 numbers too. Nice.
The formula
If you want to count how many numbers are in a list from a to b, inclusive, here’s the rule (given that both a and b are positive and b >= a):
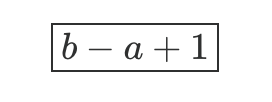
That +1 is the key.
So for our original example:
18 - 5 + 1 = 14
For the curious: formula derivation
Using the same trick, we subtract a - 1 from each number in the range from a to b. This transforms it into a list we can count easily, starting from 1:
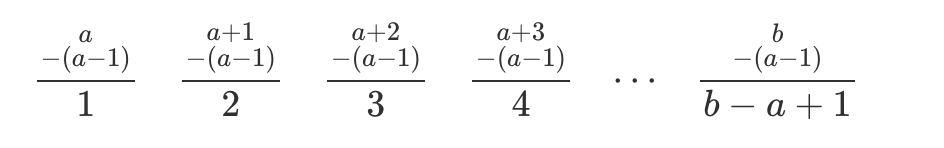
Our new list has b - a + 1 numbers, so the original list has the same count.
The +1 rule is simple, but surprisingly easy to overlook. Here’s where it often sneaks in.
Where this trips people up
This tiny +1 mistake shows up everywhere:
- Days between two calendar dates (inclusive)
- Characters in a string or line
- Steps in a workout plan
- Floors between 3 and 7 (did you forget to count the 3rd floor?)
- Loop boundaries in code (<= vs <)
Miss it, and you might:
- Pack too few t-shirts for your vacation
- Underestimate your timeline
- Overrun an array and ship a bug
It’s such a common mistake, it even has a name: the off-by-one error. Software engineers run into it constantly, but it affects everyone.
Once you understand it, you’ll start spotting it everywhere. In code, in calendars, in life.
P.S. If you feel extra adventurous, try the following exercises:
- How many numbers are in the range from 42 to 58, inclusive?
- Derive the formula b - a + 1 from scratch, no peeking
- How many numbers are in the list 6, 8, 10, 12, …, 128, 130? (Hint: What do you need to do before applying the formula b - a + 1?)
Stay tuned for more. And count carefully.
Originally published in my newsletter Beyond Basics. If you’d like to get future posts like this by email, you can subscribe here.
Get the edge and stay sharp. Subscribe to Beyond Basics for free and get new posts without missing a beat!